Handling default parameter value in Azure DevOps
When building YAML pipeline, Azure DevOps allows you to provide a set of input parameters. Those parameters are useful when you want to customize logic inside a pipeline. Think about running different stages, jobs and steps depending on the values provided by a user when scheduling a run. There’s one gotcha here - currently, Azure DevOps disallows you from configuring optional parameters. This means, that you either always provide a value, or find another way of seeding a run (e.g. using variable groups). In this article, we’ll discuss how one can use default values of parameters, so they are meaningful and can be used as a method to skip certain fragments of a pipeline.
Building a pipeline
For the reference for this article, let’s start with the following pipeline:
trigger: none
pool:
vmImage: ubuntu-latest
parameters:
- name: environment
displayName: 'Environment'
values:
- dev
- test
- stage
- prod
jobs:
- job: Validate
steps:
- script: 'echo "Validating things..."'
- job: DeployDev
steps:
- script: 'echo "Deploying DEV..."'
- job: DeployTest
steps:
- script: 'echo "Deploying TEST..."'
- job: DeployStage
steps:
- script: 'echo "Deploying STAGE..."'
- job: DeployProd
steps:
- script: 'echo "Deploying PROD..."'
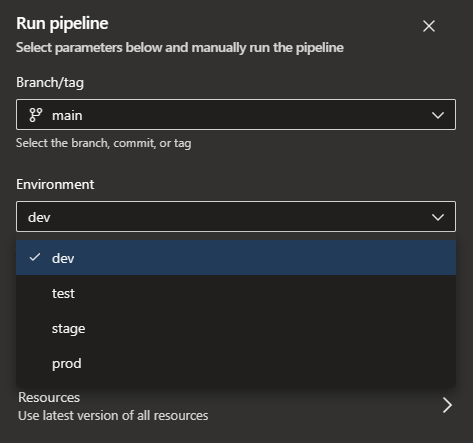
This pipeline has 5 jobs - one, which could run some kind of validation scripts, and 4 jobs, which are responsible for deployment of changes to selected environment. To allow a user to select a desired environment, we also configured environment parameter. Such parameter is then available in UI when starting a run of the pipeline:
 There’s one problem to solve yet - if we run the pipeline just like that, there’s nothing, which would stop Azure DevOps from running all the jobs at one:
There’s one problem to solve yet - if we run the pipeline just like that, there’s nothing, which would stop Azure DevOps from running all the jobs at one:
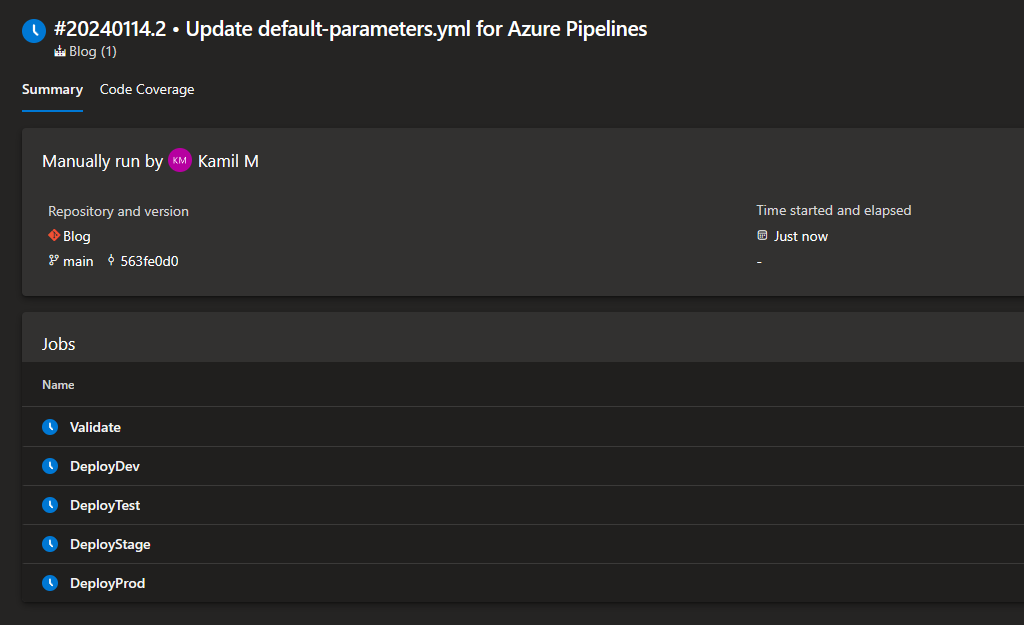 This is now what we’d like to have. Let’s fix it.
This is now what we’d like to have. Let’s fix it.
Using conditions
Azure DevOps has a feature called conditions, which allow us to decide when a certain pipeline section is supposed to run. In general, syntax for a condition looks like this:
condition: and(succeeded(), eq(variables.isMain, true))
In the above example, a condition is based on a and() logical function, which is true only of two passed values evaluate to true. To explain the example even more - it will return true only if:
- previous dependency (like job, step, stage) succeeded (hence
succeeded()) - value of
isMainvariable is set totrue
We understand the conditions a bit better now - it’s time to use them in our pipeline. As in our condition we’d like to use a parameter, we need to implement slightly different syntax:
trigger: none
pool:
vmImage: ubuntu-latest
parameters:
- name: environment
displayName: 'Environment'
values:
- dev
- test
- stage
- prod
jobs:
- job: Validate
steps:
- script: 'echo "Validating things..."'
- job: DeployDev
condition: ${{ eq(parameters.environment, 'dev') }}
steps:
- script: 'echo "Deploying DEV..."'
- job: DeployTest
condition: ${{ eq(parameters.environment, 'test') }}
steps:
- script: 'echo "Deploying TEST..."'
- job: DeployStage
condition: ${{ eq(parameters.environment, 'stage') }}
steps:
- script: 'echo "Deploying STAGE..."'
- job: DeployProd
condition: ${{ eq(parameters.environment, 'prod') }}
steps:
- script: 'echo "Deploying PROD..."'
From now on, every time we select a desired environment, deployment should happen only for a single job. Here’s an example when choosing dev as the value of our parameter:
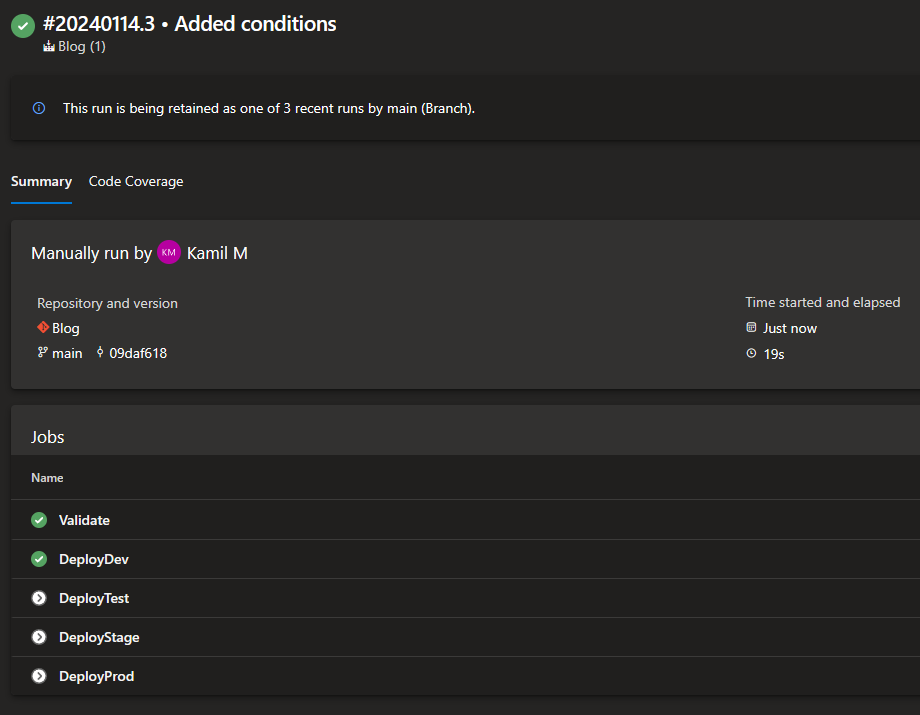 Looks good so far. Everything works except one tiny detail - we’re unable to run the initial job
Looks good so far. Everything works except one tiny detail - we’re unable to run the initial job Validate alone. Doing so seems like a neat idea, especially for quick tests whether our changes have a chance to be deployed successfully. Let’s try to implement an improvement.
Adding a new value
The initial idea to solve the problem with the Validate job is adding one more value to the parameter:
parameters:
- name: environment
displayName: 'Environment'
values:
- validate
- dev
- test
- stage
- prod
Now, with a small change to our pipeline, we could make sure, that the job can be run alone:
jobs:
- job: Validate
condition: ${{ eq(parameters.environment, 'validate') }}
steps:
- script: 'echo "Validating things..."'
Such change will work just fine, but once again there’s a problem - we’re unable to run both Validate jobs and any of the deployment jobs since now there’s a strict condition, which blocks other jobs. The question is - how could we configure the pipeline, so we can run both Validate job in isolation, but also let it run as a preflight validation for any other job in the pipeline?
Creating a ghost job
To fix our issue, we can introduce something, which I call a ghost job. In short, it’s a simple concept, where a job inside a pipeline implicitly depends on a provided input, so it can run in isolation or with other jobs, even though the input value is not passed explicitly. Let’s check the following example:
trigger: none
pool:
vmImage: ubuntu-latest
parameters:
- name: environment
displayName: 'Environment'
default: validate-only
values:
- validate-only
- dev
- test
- stage
- prod
jobs:
- job: Validate
steps:
- script: 'echo "Validating things..."'
- job: DeployDev
condition: ${{ eq(parameters.environment, 'dev') }}
steps:
- script: 'echo "Deploying DEV..."'
- job: DeployTest
condition: ${{ eq(parameters.environment, 'test') }}
steps:
- script: 'echo "Deploying TEST..."'
- job: DeployStage
condition: ${{ eq(parameters.environment, 'stage') }}
steps:
- script: 'echo "Deploying STAGE..."'
- job: DeployProd
condition: ${{ eq(parameters.environment, 'prod') }}
steps:
- script: 'echo "Deploying PROD..."'
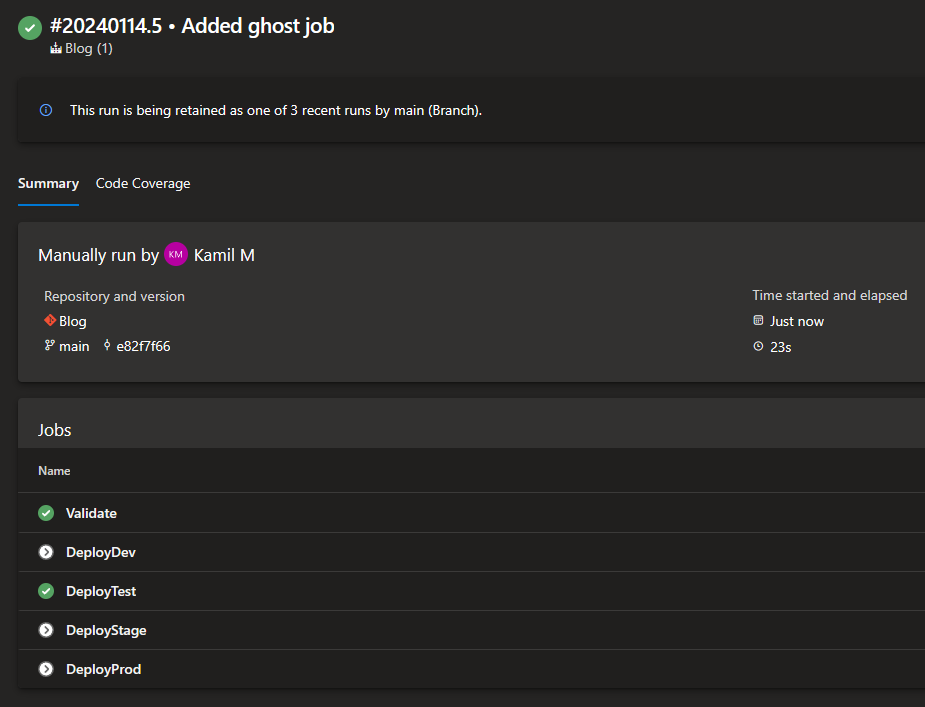
As you can see, I got rid of condition in our Validate job. I also added new value for the environment parameter called validate-only and made it the default value. Now, if you just run the pipeline without selecting an environment, it’ll run the Validate job only:
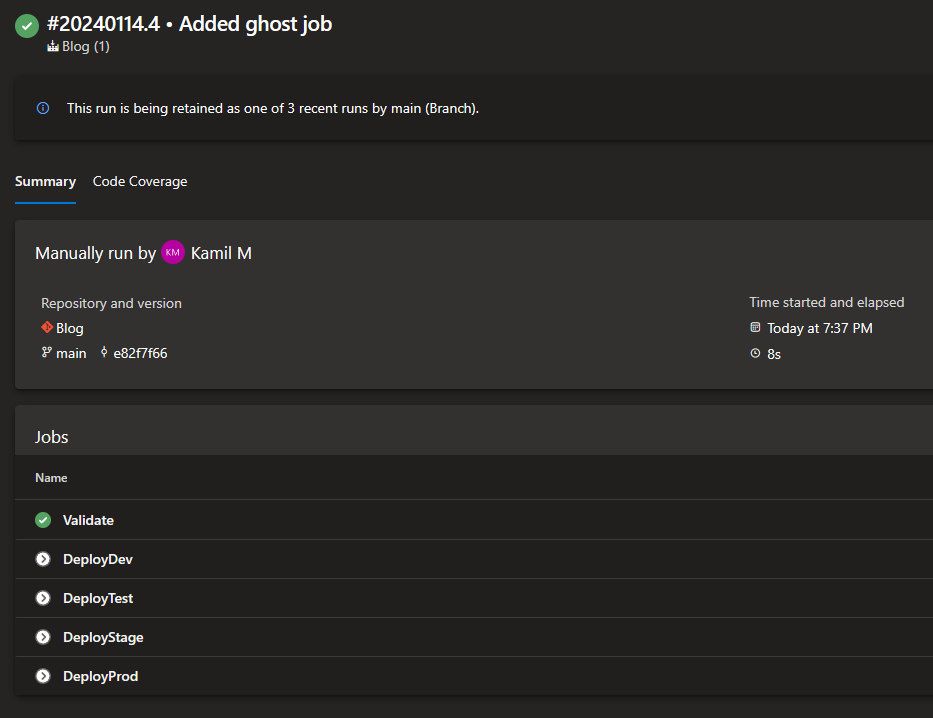 However, selecting any of other values, will trigger both
However, selecting any of other values, will trigger both Validate job and one of the deployment jobs. Here’s example when test was selected:
 It’s a simple and efficient concepts, which has also one significant advantage over other ideas (like using empty value or additional condition with boolean value) - it allows you to keep the configuration of a pipeline clear, while make sure, that each value provided has a certain meaning in a pipeline.
It’s a simple and efficient concepts, which has also one significant advantage over other ideas (like using empty value or additional condition with boolean value) - it allows you to keep the configuration of a pipeline clear, while make sure, that each value provided has a certain meaning in a pipeline.